[Spring-Reactive] Reactor (Context, Debugging)
in Spring on Spring
Context
- Reactor Sequence 상에서 상태를 저장할 수 있고, 저장된 상태 값을 Operator 체인에서 공유해서 사용할 수 있는 인터페이스이다.
- Context에 값을 저장하기 위해서는 contextWrite( )을 사용한다.
- Context에서 값을 읽어오기 위해서는 읽기 전용 뷰인 ContextView를 사용한다.
- ContextView는 Reactor Sequence에서 deferContextual() 또는 transformDeferredContextual()을 통해서 제공된다.
- Context에서 값만 꺼내 쓰면 deferContextual()
- Context에 따라 원래 체인을 바꾸고 싶으면 transformDeferredContextual()
Reactor Sequence란?
- Reactor에서 Sequence는 데이터 스트림 또는 데이터 흐름을 의미한다. 이 스트림은 비동기적으로 데이터를 방출하고, 처리하며, 종료되는 일련의 과정을 의미한다.
자주 사용되는 Context API
- put(key, value) : key/value 형태로 Context에 값을 쓴다.
- Context.of(key1, value2, key2, value2, …) : key/value 형태로 Context에 여러개의 값을 쓴다.
- putAll(ContextView) : 파라미터로 입력된 ContextView를 merge 한다.
- delete(key) : Context에서 key에 해당하는 value를 삭제한다.
- get(key) : ContextView에서 key에 해당하는 value를 반환한다.
- getOrEmpty(key) : ContextView에서 key에 해당하는 value를 Optional로 래핑해서 반환한다.
- getOrDefault(key, default value) : ContextView에서 key에 해당하는 value를 가져온다. key에 해당하는 value가 없으면 default value를 가져온다.
- hasKey(key) : ContextView에서 특정 key가 존재하는지를 확인한다.
- isEmpty() : Context가 비어있는지 확인한다.
- size() : Context내에 있는 key/value 의 개수를 반환한다.
Context의 특징
- Context는 각각의 Subscriber를 통해 Reactor Sequence에 연결 되며 체인에서 각각의 Operator들이 실행 쓰레드가 달라도 연결된 Context에 접근할 수 있다.
- Context는 체인의 맨 아래에서부터 위로 전파된다.
- Context는 Downstream 에서 Upstream으로 전파 된다.
- Operator 체인에서 Context read 메서드가 Context write 메서드 밑에 있을 경우에는 write된 값을 read할 수 없다.
- 따라서 일반적으로 Context에 write 할때에는 Operator 체인의 마지막에 둔다.
- 동일한 키에 대해서 write 할 경우, 값을 덮어쓴다.
- 메인 Operator 내부에서 Sequence를 생성하는 flatMap( ) 같은 Operator내에서 write 된 Context의 값은 Inner Sequence 내부에서만 유효하고, 외부 Operator 체인에서는 보이지 않는다.
contextWrite, deferContextual, transformDeferredContextual
/**
* Context 개념 설명 예제 코드
* - contextWrite()으로 Context에 값을 쓸 수 있고, ContextView.get()을 통해서 Context에 저장된 값을 read 할 수 있다.
* - ContextView는 deferContextual() 또는 transformDeferredContextual()을 통해 제공된다.
*/
public class ContextIntroduceExample01 {
public static void main(String[] args) {
String key = "message";
Mono<String> mono = Mono.deferContextual(ctx ->
Mono.just("Hello" + " " + ctx.get(key)).doOnNext(Logger::doOnNext)
)
.subscribeOn(Schedulers.boundedElastic())
.publishOn(Schedulers.parallel())
.transformDeferredContextual((mono2, ctx) -> mono2.map(data -> data + " " + ctx.get(key)))
.contextWrite(context -> context.put(key, "Reactor"));
mono.subscribe(data -> Logger.onNext(data));
TimeUtils.sleep(100L);
}
}
동작 순서
- contextWrite
- deferContextual(Hello message Reactor)
- transformDeferredContextual(Hello message Reactor Reactor)
Context.of
/**
* Context API 중에서 write API 예제 코드
* - Context.of(...) 사용
*/
public class ContextAPIExample01 {
public static void main(String[] args) {
String key1 = "id";
String key2 = "name";
Mono<String> mono =
Mono.deferContextual(ctx ->
Mono.just("ID: " + " " + ctx.get(key1) + ", " + "Name: " + ctx.get(key2))
)
.publishOn(Schedulers.parallel())
.contextWrite(Context.of(key1, "itVillage", key2, "Kevin"));
mono.subscribe(data -> Logger.onNext(data));
TimeUtils.sleep(100L);
}
}
pullAll
/**
* Context API 예제 코드
* - pullAll(ContextView) API 사용
*/
public class ContextAPIExample02 {
public static void main(String[] args) {
String key1 = "id";
String key2 = "name";
String key3 = "country";
Mono.deferContextual(ctx ->
Mono.just("ID: " + " " + ctx.get(key1) + ", " + "Name: " + ctx.get(key2) +
", " + "Country: " + ctx.get(key3))
)
.publishOn(Schedulers.parallel())
.contextWrite(context -> context.putAll(Context.of(key2, "Kevin", key3, "Korea").readOnly()))
.contextWrite(context -> context.put(key1, "itVillage"))
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
특징 실행
- Context는 구독(Subscriber)마다 독립적으로 생성된다.
- 즉, subscribe() 할 때마다 그 구독만을 위한 Context가 생긴다.
- Context는 연산자 체인의 아래에서 위로 전달된다.
- 같은 키가 중복되면, 가장 나중에 작성된 contextWrite() 값이 우선 적용된다.
/**
* Context의 특징
* - Context는 각각의 구독을 통해 Reactor Sequence에 연결 되며 체인의 각 연산자가 연결된 Context에 접근할 수 있어야 한다.
*
*/
public class ContextFetureExample01 {
public static void main(String[] args) {
String key1 = "id";
Mono<String> mono = Mono.deferContextual(ctx ->
Mono.just("ID: " + " " + ctx.get(key1))
)
.publishOn(Schedulers.parallel());
mono.contextWrite(context -> context.put(key1, "itVillage"))
.subscribe(data -> Logger.onNext("subscriber 1", data));
mono.contextWrite(context -> context.put(key1, "itWorld"))
.subscribe(data -> Logger.onNext("subscriber 2", data));
TimeUtils.sleep(100L);
}
}
- Context는 Operator 체인의 아래에서 위로 전파된다.
- 가장 마지막에 위치한 contextWrite()의 값이 최종 적용된다.
- transformDeferredContextual() 시점엔 name이 아직 없어서 getOrDefault()로 기본값이 사용됨.
- 만약 get()을 썼다면 NoSuchElementException이 났을 것.
- Inner Sequence 안에서는 외부 Context 값을 읽을 수 있지만, 외부에서는 Inner Sequence 안의 Context를 읽을 수 없다.
/**
* Context의 특징
* - Context는 체인의 맨 아래에서부터 위로 전파된다.
* - 따라서 Operator 체인에서 Context read 읽는 동작이 Context write 동작 밑에 있을 경우에는 write된 값을 read할 수 없다.
* - 결과는 Kevin이 아닌 Tom이 출력 된다.
*/
public class ContextFetureExample02 {
public static void main(String[] args) {
final String key1 = "id";
final String key2 = "name";
Mono
.deferContextual(ctx ->
Mono.just(ctx.get(key1))
)
.publishOn(Schedulers.parallel())
.contextWrite(context -> context.put(key2, "Kevin"))
.transformDeferredContextual((mono, ctx) ->
mono.map(data -> data + ", " + ctx.getOrDefault(key2, "Tom"))
)
.contextWrite(context -> context.put(key1, "itVillage"))
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
/**
* Context의 특징
* - 동일한 키에 대해서 write 할 경우, 해당 키에 대한 값을 덮어 쓴다.
* - 결과는 itWorld 가 출력 된다.(contextWrite 는 아래서 부터 위로 실행 된다)
*/
public class ContextFetureExample03 {
public static void main(String[] args) {
String key1 = "id";
Mono.deferContextual(ctx ->
Mono.just("ID: " + " " + ctx.get(key1))
)
.publishOn(Schedulers.parallel())
.contextWrite(context -> context.put(key1, "itWorld"))
.contextWrite(context -> context.put(key1, "itVillage"))
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
- Inner Sequence(예: flatMap 내부)에서는 바깥쪽 Context 값을 읽을 수 있다.
- 하지만 바깥쪽 Sequence에서는 Inner Context 값을 읽을 수 없다.
job:Software Engineer는 Inner에서 등록 → Inner에서 접근 가능id:itVillage은 Outer에서 등록 → Inner에서도 접근 가능- 하지만 Outer에서
job을 읽으려고 하면 X → NoSuchElementException 발생
/**
* Context의 특징
* - inner Sequence 내부에서는 외부 Context에 저장된 데이터를 읽을 수 있다.
* - inner Sequence 내부에서 Context에 저장된 데이터는 inner Sequence 외부에서 읽을 수 없다.
* - 결과 : 외부 transformDeferredContextual 부분을 주석 처리시 잘 나온다.
* - 결과 : 외부 transformDeferredContextual 부분을 주석 처리 하지 않았을 경우 에러.
*/
public class ContextFetureExample04 {
public static void main(String[] args) {
String key1 = "id";
Mono.just("Kevin")
.transformDeferredContextual((stringMono, contextView) -> contextView.get("job"))
.flatMap(name -> Mono.deferContextual(ctx ->
Mono.just(ctx.get(key1) + ", " + name)
.transformDeferredContextual((mono, innerCtx) ->
mono.map(data -> data + ", " + innerCtx.get("job"))
)
.contextWrite(context -> context.put("job", "Software Engineer"))
)
)
.publishOn(Schedulers.parallel())
.contextWrite(context -> context.put(key1, "itVillage"))
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
Context 활용: 인증 토큰 전달)
Context는 인증 토큰처럼 직교성(독립성)이 높은 정보 전달에 적합하다.contextWrite()는 구독 직전에 위치해야 Operator 체인 전체에 전파된다.deferContextual()로 Context에서 값을 꺼내 사용할 수 있다.- 결과적으로, 비즈니스 로직(postBook)과 인증 정보가 분리되어 코드가 깔끔해진다.
@Slf4j
public class Example11_8 {
public static final String HEADER_AUTH_TOKEN = "authToken";
public static void main(String[] args) {
Mono<String> mono = postBook(
Mono.just(new Book("abcd-1111-3533-2809", "Reactor's Bible", "Kevin"))
).contextWrite(Context.of(HEADER_AUTH_TOKEN, "eyJhbGciOi...")); // Context에 토큰 저장
mono.subscribe(data -> log.info("# onNext: {}", data));
}
private static Mono<String> postBook(Mono<Book> book) {
return Mono.zip(
book,
Mono.deferContextual(ctx -> Mono.just(ctx.get(HEADER_AUTH_TOKEN)))
).flatMap(tuple -> {
String response = "POST the book(" + tuple.getT1().getBookName() +
"," + tuple.getT1().getAuthor() + ") with token: " + tuple.getT2();
return Mono.just(response); // HTTP POST 전송했다고 가정
});
}
@AllArgsConstructor
@Data
static class Book {
private String isbn;
private String bookName;
private String author;
}
}
Reactor에서의 Debugging 하는 3가지 방법
- Debug 모드를 활성화 하는 방법(Globally).
- checkpoint( ) Operator를 사용하는 방법(Locally).
- log( ) operator를 사용해서 Reactor Sequence에서 발생하는 Signal을 확인하는 방법
Debugging 용어
- stacktrace : 호출된 메서드에 대한 Stack Frame에 대한 리포트
assembly: Mono 또는 Flux가 선언된 지점- traceback :
- 실패한 operator의 stacktrace를 캡처한 정보
- suppressed exception 형태로 original stacktrace에 추가된다.
프로덕션 환경에서의 디버깅 설정
Reactor는 프로덕션 환경에서도 스택 트레이스 캡쳐 비용 없이 디버깅 정보를 제공하기 위해 별도 Java 에이전트(ReactorDebugAgent)를 지원한다.
이를 사용하려면 reactor-tools 의존성을 추가해야 하며, spring.reactor.debug-agent.enabled=true로 설정하면 애플리케이션 시작 시 자동으로 ReactorDebugAgent가 활성화된다.
만약 false로 설정하면, 직접 ReactorDebugAgent.init()을 호출해야 한다.
Spring Boot에서는 기본값이 true로 설정되어 있다.
1) Debug 모드
- Debug 모드 시, Operator의 stacktrace capturing을 통해 디버깅에 필요한 정보를 측정한다.
- Hooks.onOperatorDebug()를 통해서 Debug 모드를 활성화 할 수 있다.
- Hooks.onOperatorDebug()는 Operator 체인이 선언되기 전에 수행되어야 한다.
- Debug 모드를 활성화 하면 Operator 체인에서 에러 발생 시, 에러가 발생한 Operator의 위치를 알려준다.
- 사용이 쉽지만 애플리케이션 내 모든 Operator의 assembly(New Flux or Mono)를 캡처하기 때문에 비용이 많이 든다.
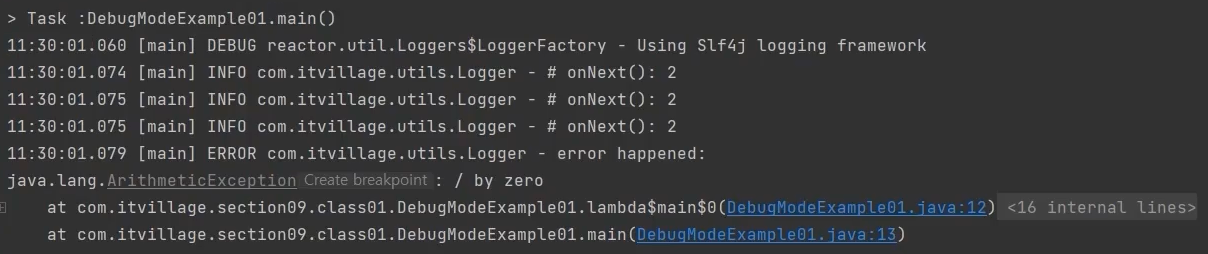
/**
* Non-Debug mode
* 어디서 에러가 난건지 명확하지 않다
*/
public class DebugModeExample01 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.subscribe(Logger::onNext, Logger::onError);
}
}
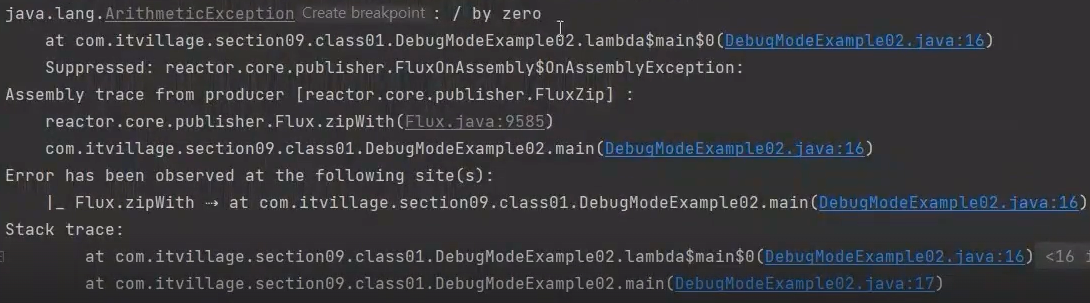
/**
* onOperatorDebug() Hook 메서드를 이용한 Debug mode
* - 애플리케이션 전체에서 global 하게 동작한다.
* - 하지만 성능 이슈가 있음
*/
public class DebugModeExample02 {
public static void main(String[] args) {
Hooks.onOperatorDebug();
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.subscribe(Logger::onNext, Logger::onError);
}
}
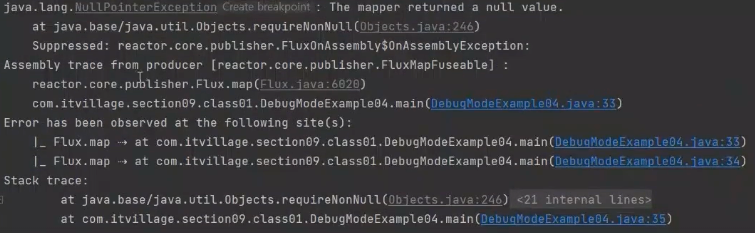
/**
* onOperatorDebug() Hook 메서드를 이용한 Debug mode 예제
*/
public class DebugModeExample04 {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("grape", "포도");
}
public static void main(String[] args) {
Hooks.onOperatorDebug();
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.map(String::toLowerCase)
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.map(fruits::get)
.map(translated -> "맛있는 " + translated)
.subscribe(Logger::onNext, Logger::onError);
}
}
2) checkpoint
- 특정 Operator 체인 내에서만 assembly stacktrace를 캡쳐한다.
- checkpoint(description)를 사용하면 에러 발생 시, chpeckpoint(description)를 추가한 지점의 assembly stacktrace를 생략하고 description을 통해 에러 발생 지점을 예상할 수 있다.
- checkpoint(description, true) = checkpoint( ) + checkpoint(“description”)
- 에러 발생 시, 고유한 식별자 등의 description과 assembly stack trace(traceback)를 모두 출력한다.
/**
* checkpoint() Operator 를 이용한 예제
* - 에러가 예상되는 assembly 지점에 checkpoint()를 사용해서 에러 발생 지점을 확인할 수 있다.
* - checkpoint()는 에러 발생 시, traceback 이 추가된다. 에러가 발생 하지 않으면 지나간다.
*/
public class CheckpointExample01 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint()
.map(num -> num + 2)
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* checkpoint() Operator 를 사용한 예제
* - 발생한 에러는 Operator 체인에 전파가 되기때문에 에러가 전파된 지점의 checkpoint()에서 확인할 수 있다.
* - 직접적으로 발생한 지점인지 아니면 에러가 전파된 지점인지 알기는 어려울 수 있다. 이럴 경우 다음 예제 처럼 추가로 checkpoint()를 추가해 확인 가능하다.
* - traceback 은 실제 에러가 발생한 assembly 지점 또는 에러가 전파된 assembly 지점의 traceback 즉,
* 실제 checkpoint()를 추가한 지점의 traceback 이 추가된다.
*/
public class CheckpointExample02 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.map(num -> num + 2)
.checkpoint()
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* checkpoint() Operator 를 2개 사용한 예제
* - 발생한 에러는 Operator 체인에 전파가 되기때문에 각각의 checkpoint()에서 확인할 수 있다.
*/
public class CheckpointExample03 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint()
.map(num -> num + 2)
.checkpoint()
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* checkpoint(description) Operator 를 이용한 예제
* - description 을 추가해서 에러가 발생한 지점을 구분할 수 있다.
* - description 을 지정할 경우에 에러가 발생한 assembly 지점의 traceback 을 추가하지 않는다.
*/
public class CheckpointExample04 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint("CheckpointExample02.zipWith.checkpoint")
.map(num -> num + 2)
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* checkpoint(description) Operator 를 2개 사용한 예제
* - 식별자를 추가해서 에러가 발생한 지점을 구분할 수 있다.
* - 식별자를 지정할 경우에 에러가 발생한 assembly 지점의 traceback 을 추가하지 않는다.
*/
public class CheckpointExample05 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint("CheckpointExample02.zipWith.checkpoint")
.map(num -> num + 2)
.checkpoint("CheckpointExample02.map.checkpoint")
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* checkpoint(description, true/false) Operator 를 이용한 예제
* - description 도 사용하고, 에러가 발생한 assembly 지점 또는 에러가 전파된 assembly 지점의 traceback 도 추가한다.
*/
public class CheckpointExample06 {
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint("CheckpointExample02.zipWith.checkpoint", true)
.map(num -> num + 2)
.checkpoint("CheckpointExample02.map.checkpoint", true)
.subscribe(Logger::onNext, Logger::onError);
}
}
/**
* 분리된 method 에서 checkpoint() Operator 를 이용한 예제
*/
public class CheckpointExample07 {
public static void main(String[] args) {
Flux<Integer> source = Flux.just(2, 4, 6, 8);
Flux<Integer> other = Flux.just(1, 2, 3, 0);
Flux<Integer> multiplySource = divide(source, other).checkpoint();
Flux<Integer> plusSource = plus(multiplySource).checkpoint();
plusSource.subscribe(Logger::onNext, Logger::onError);
}
private static Flux<Integer> divide(Flux<Integer> source, Flux<Integer> other) {
return source.zipWith(other, (x, y) -> x/y);
}
private static Flux<Integer> plus(Flux<Integer> source) {
return source.map(num -> num + 2);
}
}
3) log
- Flux 또는 Mono에서 발생하는 signal event를 출력해준다.(onNext, onError, onComplete, subscriptions, cancellations, requests)
- Reactor Sequence의 동작을 로그로 출력.
- 여러개의 log()를 사용할 수 있으며, Operator 마다 전파되는 singal event를 확인할 수 있다.
- Custom Category를 입력해서 Operator 마다 출력되는 signal event를 구분할 수 있다.
- 에러 발생 시, stacktrace도 출력해준다.
- debug mode 라면 traceback도 출력해준다.
/**
* log() operator를 사용한 예제
* melon 이라는 문자열을 emit 했지만 두 번째 map() 이후의 어떤 지점에서 melon 문자열을 처리하는 중에 에러가 발생했음을 의미
* .log("Fruit.Substring", Level.FINE) 과 같이 바꿔서 코스 실행시 로그 레벨이 모두 DEBUG로 바뀌고 "Fruit.Substring" 카테고리까지 표히새 준다.
*/
public class LogOperatorExample01 {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("grape", "포도");
}
public static void main(String[] args) {
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.log()
.map(String::toLowerCase)
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.map(fruits::get)
.subscribe(Logger::onNext, Logger::onError);
}
}
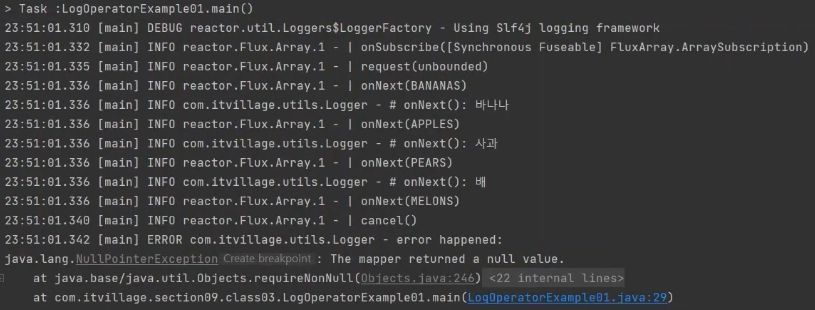
/**
* log() operator와 Debug mode 를 같이 사용한 예제
* - log()는 에러 발생 시, stacktrace와 함께 traceback도 같이 출력한다.
*/
public class LogOperatorExample02 {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("grape", "포도");
}
public static void main(String[] args) {
Hooks.onOperatorDebug();
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.log()
.map(String::toLowerCase)
.log()
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.log()
.map(fruits::get)
.log()
.subscribe(Logger::onNext, Logger::onError);
}
}
로그 분석
- OnAssembly.(숫자는 위에서 부터 오퍼레이터 순서)
- log()는 바로 위에 있는 오퍼레이터의 로그를 출력한다
16:04:29.848 [main] INFO reactor.Flux.OnAssembly.1 -- | onSubscribe([Fuseable] FluxOnAssembly.OnAssemblySubscriber)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.2 -- | onSubscribe([Fuseable] FluxOnAssembly.OnAssemblySubscriber)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.3 -- | onSubscribe([Fuseable] FluxOnAssembly.OnAssemblySubscriber)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.4 -- | onSubscribe([Fuseable] FluxOnAssembly.OnAssemblySubscriber)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.4 -- | request(unbounded)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.3 -- | request(unbounded)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.2 -- | request(unbounded)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.1 -- | request(unbounded)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.1 -- | onNext(BANANAS)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.2 -- | onNext(bananas)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.3 -- | onNext(banana)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.4 -- | onNext(바나나)
16:04:29.850 [main] INFO test.reactor.util.Logger -- # onNext(): 바나나
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.1 -- | onNext(APPLES)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.2 -- | onNext(apples)
16:04:29.850 [main] INFO reactor.Flux.OnAssembly.3 -- | onNext(apple)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.4 -- | onNext(사과)
16:04:29.851 [main] INFO test.reactor.util.Logger -- # onNext(): 사과
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.1 -- | onNext(PEARS)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.2 -- | onNext(pears)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.3 -- | onNext(pear)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.4 -- | onNext(배)
16:04:29.851 [main] INFO test.reactor.util.Logger -- # onNext(): 배
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.1 -- | onNext(MELONS)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.2 -- | onNext(melons)
16:04:29.851 [main] INFO reactor.Flux.OnAssembly.3 -- | onNext(melon)
16:04:29.852 [main] INFO reactor.Flux.OnAssembly.3 -- | cancel()
16:04:29.852 [main] INFO reactor.Flux.OnAssembly.2 -- | cancel()
16:04:29.852 [main] INFO reactor.Flux.OnAssembly.1 -- | cancel()
16:04:29.855 [main] ERROR reactor.Flux.OnAssembly.4 -- | onError(java.lang.NullPointerException: The mapper [test.reactor.section09.class01.CheckpointExample04$$Lambda/0x0000000401082cc8] returned a null value.)
16:04:29.855 [main] ERROR reactor.Flux.OnAssembly.4 --
/**
* log() operator Custom Category 를 사용하는 예제
*/
public class LogOperatorExample03 {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("grape", "포도");
}
public static void main(String[] args) {
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.subscribeOn(Schedulers.boundedElastic())
.log("Fruit.Source")
.publishOn(Schedulers.parallel())
.map(String::toLowerCase)
.log("Fruit.Lower")
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.log("Fruit.Substring")
.map(fruits::get)
.log("Fruit.Name")
.subscribe(Logger::onNext, Logger::onError);
TimeUtils.sleep(100L);
}
}
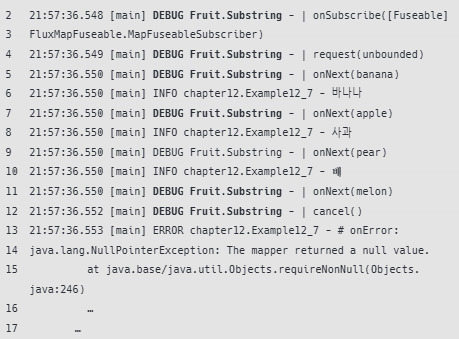
16:10:37.846 [boundedElastic-1] INFO Fruit.Source -- onNext(BANANAS)
16:10:37.846 [boundedElastic-1] INFO Fruit.Source -- onNext(APPLES)
16:10:37.846 [boundedElastic-1] INFO Fruit.Source -- onNext(PEARS)
16:10:37.846 [boundedElastic-1] INFO Fruit.Source -- onNext(MELONS)
16:10:37.846 [parallel-1] INFO Fruit.Lower -- | onNext(bananas)
16:10:37.846 [parallel-1] INFO Fruit.Substring -- | onNext(banana)
16:10:37.846 [parallel-1] INFO Fruit.Name -- | onNext(바나나)
16:10:37.846 [boundedElastic-1] INFO Fruit.Source -- onComplete()
16:10:37.846 [parallel-1] INFO test.reactor.util.Logger -- # onNext(): 바나나
16:10:37.846 [parallel-1] INFO Fruit.Lower -- | onNext(apples)
16:10:37.846 [parallel-1] INFO Fruit.Substring -- | onNext(apple)
16:10:37.846 [parallel-1] INFO Fruit.Name -- | onNext(사과)
16:10:37.847 [parallel-1] INFO test.reactor.util.Logger -- # onNext(): 사과
16:10:37.847 [parallel-1] INFO Fruit.Lower -- | onNext(pears)
16:10:37.847 [parallel-1] INFO Fruit.Substring -- | onNext(pear)
16:10:37.847 [parallel-1] INFO Fruit.Name -- | onNext(배)
16:10:37.847 [parallel-1] INFO test.reactor.util.Logger -- # onNext(): 배
16:10:37.847 [parallel-1] INFO Fruit.Lower -- | onNext(melons)
16:10:37.847 [parallel-1] INFO Fruit.Substring -- | onNext(melon)
16:10:37.848 [parallel-1] INFO Fruit.Substring -- | cancel()
16:10:37.848 [parallel-1] INFO Fruit.Lower -- | cancel()
16:10:37.848 [parallel-1] INFO Fruit.Source -- cancel()
16:10:37.848 [parallel-1] ERROR Fruit.Name -- | onError(java.lang.NullPointerException: The mapper [test.reactor.section09.class01.CheckpointExample04$$Lambda/0x000000700109eab8] returned a null value.)