[Spring-Reactive] Reactor (Scheduler)
in Spring on Spring
스레드(Thread) 개념
- 물리적인 스레드 (Physical Thread)
- CPU 코어에서 실제로 명령을 처리하는 하드웨어 단위. 병렬성(Parallelism)과 관련됨.
- 논리적인 스레드 (Logical Thread)
- 소프트웨어에서 생성된 실행 단위. 동시에 실행되는 것처럼 보이며, 동시성(Concurrency)과 관련됨.
- 하나의 물리 코어는 여러 논리 스레드를 번갈아 빠르게 실행하여 동시에 실행되는 것처럼 보이게 함.
- 흔히 CPU 사양에서 ‘4코어 8스레드’라고 하면, 4개의 물리적 코어와 8개의 논리적 스레드를 의미.
병렬성(Parallelism) vs 동시성(Concurrency)
| 구분 | 병렬성 (Parallelism) | 동시성 (Concurrency) |
|---|---|---|
| 정의 | 여러 작업을 실제로 동시에 수행 | 여러 작업을 동시에 수행되는 것처럼 처리 |
| 관련 요소 | 물리적인 스레드 (Physical Thread) | 논리적인 스레드 (Logical Thread) |
| 예시 | 4개의 코어가 4개의 작업을 동시에 실행 | 1개의 코어가 4개의 작업을 빠르게 번갈아 실행 |
| 유형 | 하드웨어 기반 실행 | 소프트웨어 기반 스케줄링 |
Scheduler란?
- Reactor에서 Scheduler는 어떤 스레드에서 실행할지 정하는 도구. 경쟁 조건 방지, 코드 단순화, 비동기 흐름 제어에 도움을 줌.
- Scheduler를 위한 전용 Operator :
- publishOn( ) : Operator 체인에서 Downstream Operator의 실행을 위한 쓰레드를 지정한다.
- subscribeOn( ) : 최상위 Upstream Publisher의 실행을 위한 쓰레드를 지정한다. 즉, 원본 데이터 소스를 emit 하기 위한 스케줄러를 지정한다.
- parallel( ) : Downstream에 대한 데이터 처리를 병렬로 분할 처리하기 위한 쓰레드를 지정한다.
parallel
subscribeOn(), publishOn()의 경우 동시성을 가지는 논리적인 스레드에 해당되지만 parallel()은 병렬성을 가지는 물리적인 스레드(라운드 로빈 방식)
import com.itvillage.utils.Logger;
import reactor.core.publisher.Flux;
/**
* parallel()만 사용할 경우에는 병렬로 작업을 수행하지 않는다.
*/
public class ParallelExample01 {
public static void main(String[] args) {
Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15})
.parallel()
.subscribe(Logger::onNext);
}
}
/**
* - parallel()만 사용할 경우에는 병렬로 작업을 수행하지 않는다.
* - runOn()을 사용해서 Scheduler를 할당해주어야 병렬로 작업을 수행한다.
* - **** CPU 코어 갯수내에서 worker thread를 할당한다. ****
*/
public class ParallelExample03 {
public static void main(String[] args) {
Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19})
.parallel()
.runOn(Schedulers.parallel())
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
/**
* - parallel()만 사용할 경우에는 병렬로 작업을 수행하지 않는다.
* - runOn()을 사용해서 Scheduler를 할당해주어야 병렬로 작업을 수행한다.
* - **** CPU 코어 갯수에 의존하지 않고, worker thread를 강제 할당한다. ****
*/
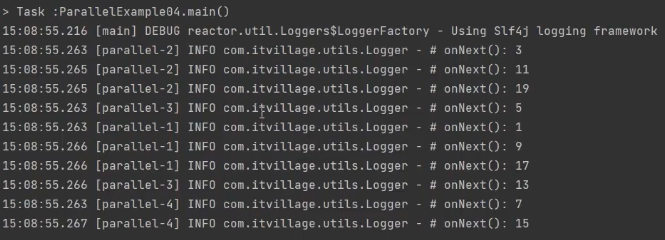
public class ParallelExample04 {
public static void main(String[] args) {
Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19})
.parallel(4)
.runOn(Schedulers.parallel())
.subscribe(Logger::onNext);
TimeUtils.sleep(100L);
}
}
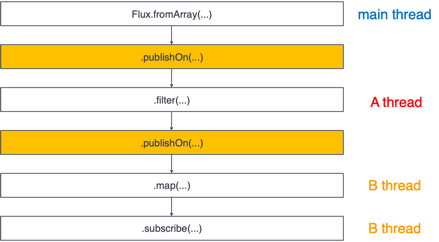
publishOn & subscribeOn
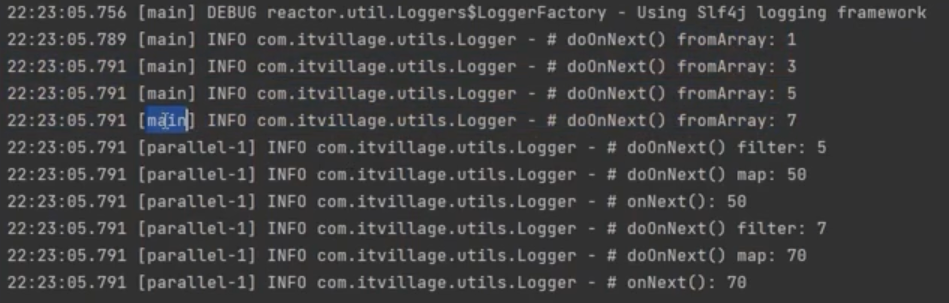
/**
* Operator 체인에서 publishOn( )이 호출되면 publishOn( ) 호출 이후의 Operator 체인은
* 다음 publisherOn( )을 만나기전까지 publishOn( )에서 지정한 Thread에서 실행이 된다.
*/
public class SchedulerOperatorExample02 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> Logger.doOnNext("fromArray", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(500L);
}
}

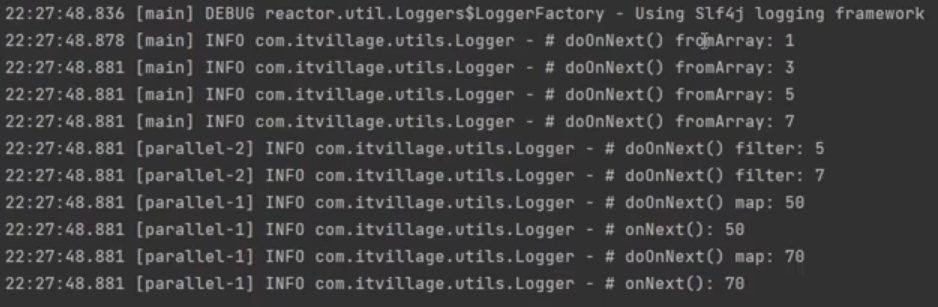
/**
* Operator 체인에서 publishOn( )이 호출되면 publishOn( ) 호출 이후의 Operator 체인은
* *** 다음 publisherOn( )을 만나기전까지 *** publishOn( )에서 지정한 Thread에서 실행이 된다.
*/
public class SchedulerOperatorExample03 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> Logger.doOnNext("fromArray", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.publishOn(Schedulers.parallel())
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(500L);
}
}
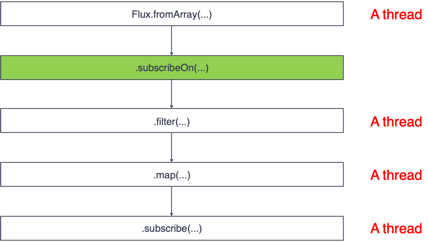
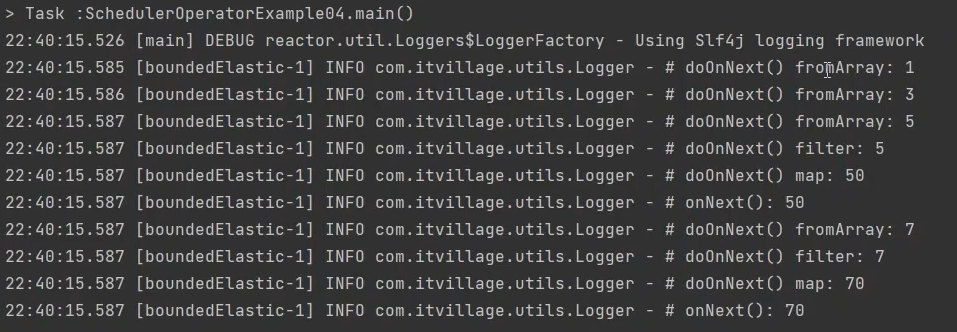
/**
* subscribeOn()은 구독 직후에 실행 될 쓰레드를 지정한다.
* 즉, 원본 Publisher의 실행 쓰레드를 subscribeOn()에서 지정한 쓰레드로 바꾼다.
*/
public class SchedulerOperatorExample04 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(data -> Logger.doOnNext("fromArray", data))
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(500L);
}
}
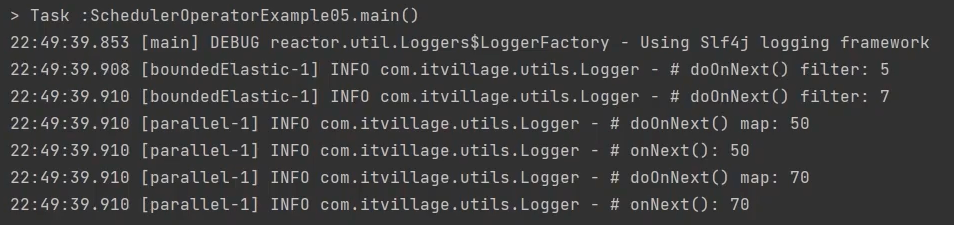
/**
* subscribeOn( )과 publishOn( )이 같이 있다면, publishOn( )을 만나기 전 까지의 Upstream Operator 체인은
* subscribeOn( )에서 지정한 쓰레드에서 실행되고, publishOn( )을 만날때마다
* publishOn( ) 아래의 Operator 체인 downstream은 publishOn( )에서 지정한 쓰레드에서 실행된다.
*/
public class SchedulerOperatorExample05 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.subscribeOn(Schedulers.boundedElastic())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.publishOn(Schedulers.parallel())
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(500L);
}
}

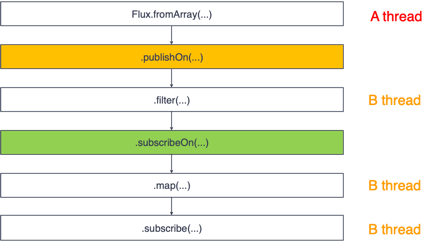
/**
* subscribeOn( )과 publishOn( )이 같이 있다면, publishOn( )을 만나기 전 까지의 Upstream Operator 체인은
* subscribeOn( )에서 지정한 쓰레드에서 실행되고, publishOn( )을 만날때마다
* publishOn( ) 아래의 Operator 체인 downstream은 publishOn( )에서 지정한 쓰레드에서 실행된다.
*/
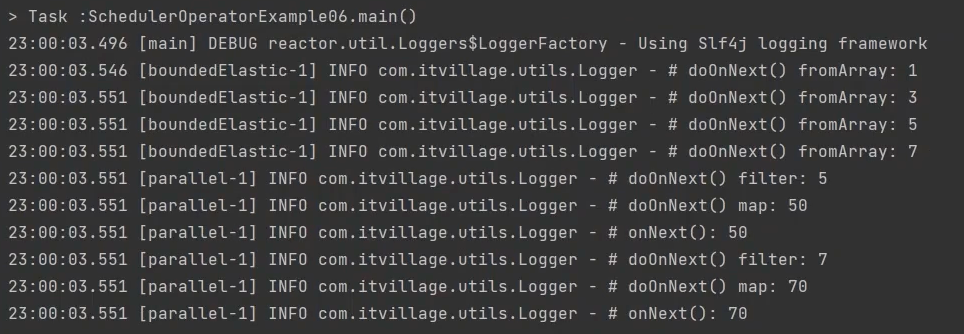
public class SchedulerOperatorExample06 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> Logger.doOnNext("fromArray", data))
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.subscribeOn(Schedulers.boundedElastic())
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(500L);
}
}
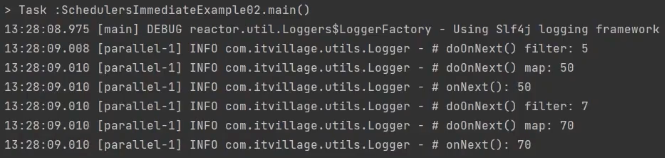
immediate
immediate를 빼나 넣나 결과는 거의 똑같다. 그런데 왜 쓰냐?
명시적 컨트롤을 위해 쓴다.
스케줄러를 조작하는 구조를 명확히 보이게 할 때
다른 사람/후임자가 코드를 볼 때 “아 여기부터는 스레드 안 바꿀거야”라고 의도 명확히 할 때
또는 코드 자동 생성기(예: Reactor 스크립트 툴)가 스케줄 변경을 일관되게 생성할 때
즉, 실질적 동작보다는 코드 명시성, 일관성 차원에서 의미가 있다.
/**
* Schedulers.immediate()을 적용 후,
* 현재 쓰레드가 할당된다.
*/
public class SchedulersImmediateExample02 {
public static void main(String[] args) {
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext("filter", data))
.publishOn(Schedulers.immediate())
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext("map", data))
.subscribe(Logger::onNext);
TimeUtils.sleep(200L);
}
}
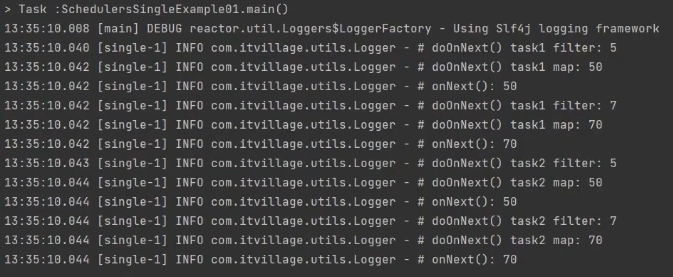
single
/**
* Schedulers.single()을 적용 할 경우,
* Schedulers.single()에서 할당된 쓰레드를 재사용 한다.
* 두번의 subscribe 모두 같은 쓰레드를 사용한다.
*/
public class SchedulersSingleExample01 {
public static void main(String[] args) {
doTask("task1")
.subscribe(Logger::onNext);
doTask("task2")
.subscribe(Logger::onNext);
TimeUtils.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.single())
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext(taskName, "filter", data))
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext(taskName, "map", data));
}
}
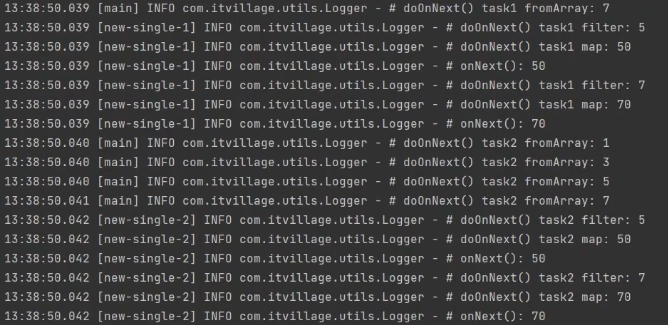
newSingle
/**
* Schedulers.single()을 적용 후,
* 첫번째 Schedulers.single()에서 할당 된 쓰레드를 재사용 한다.
* newSingle은 호출 할때 마다 매번 새로운 쓰레드를 호출한다.
*/
public class SchedulersSingleExample02 {
public static void main(String[] args) {
doTask("task1")
.subscribe(Logger::onNext);
doTask("task2")
.subscribe(Logger::onNext);
TimeUtils.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> Logger.doOnNext(taskName, "fromArray", data))
.publishOn(Schedulers.newSingle("new-single", true))
.filter(data -> data > 3)
.doOnNext(data -> Logger.doOnNext(taskName, "filter", data))
.map(data -> data * 10)
.doOnNext(data -> Logger.doOnNext(taskName, "map", data));
}
}
newBoundedElastic
/**
* Schedulers.newBoundedElastic()을 적용
* 변수 : 쓰레드 갯수, 큐 갯수, 쓰레드 이름
*/
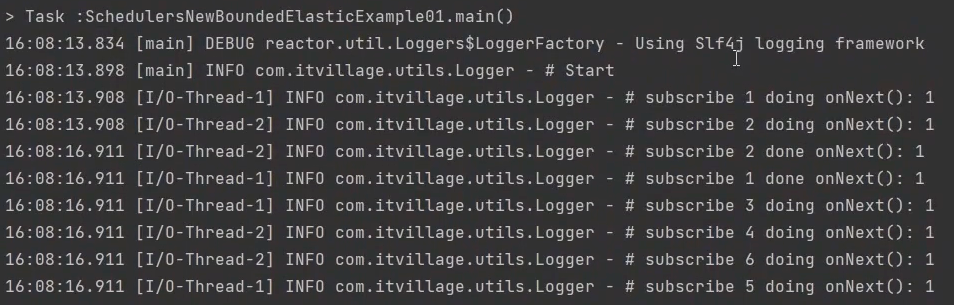
public class SchedulersNewBoundedElasticExample01 {
public static void main(String[] args) {
Scheduler scheduler = Schedulers.newBoundedElastic(2, 2, "I/O-Thread");
Mono<Integer> mono =
Mono
.just(1)
.subscribeOn(scheduler);
Logger.info("# Start");
mono.subscribe(data -> {
Logger.onNext("subscribe 1 doing", data);
TimeUtils.sleep(3000L);
Logger.onNext("subscribe 1 done", data);
});
mono.subscribe(data -> {
Logger.onNext("subscribe 2 doing", data);
TimeUtils.sleep(3000L);
Logger.onNext("subscribe 2 done", data);
});
mono.subscribe(data -> {
Logger.onNext("subscribe 3 doing", data);
});
mono.subscribe(data -> {
Logger.onNext("subscribe 4 doing", data);
});
mono.subscribe(data -> {
Logger.onNext("subscribe 5 doing", data);
});
mono.subscribe(data -> {
Logger.onNext("subscribe 6 doing", data);
});
// TimeUtils.sleep(4000L);
// scheduler.dispose();
}
}
newParallel
/**
* Schedulers.newParallel()을 적용
* 변수 : 쓰레드 이름, 쓰레드 갯수, 데몬쓰레드 동작 여부
*/
public class SchedulersNewParallelExample01 {
public static void main(String[] args) {
Mono<Integer> flux =
Mono
.just(1)
.publishOn(Schedulers.newParallel("Parallel Thread", 4, true));
flux.subscribe(data -> {
TimeUtils.sleep(5000L);
Logger.onNext("subscribe 1", data);
});
flux.subscribe(data -> {
TimeUtils.sleep(4000L);
Logger.onNext("subscribe 2", data);
});
flux.subscribe(data -> {
TimeUtils.sleep(3000L);
Logger.onNext("subscribe 3", data);
});
flux.subscribe(data -> {
TimeUtils.sleep(2000L);
Logger.onNext("subscribe 4", data);
});
TimeUtils.sleep(6000L);
}
}
