[Spring-Batch] Spring Batch
배치 서비스 기본 3단계
Read많은 데이터를 DB, file, message 로 부터 읽는다.Processing읽은 데이터를 로직에 의해 처리한다.Write로직으로 처리된 데이터를 수정된 형태로 출력한다.
tip. 배치는 알림과 모니터링 필수
배치 처리 대표적인 도구들
- Cron, Crontab
- Quartz
- Jenkins
- SpringBatch
SpringBatch
스프링 배치의 지원 기능
트랜잭션관리청크 단위의 처리- 선언적 입출력 지원
병렬처리- 시작, 중지, 재시작 지원
- 재시도 또는 건너뛰기 지원
- 웹기반 관리 인터페이스 제공 (Spring Cloud Data Flow)
스프링 배치 아키텍처
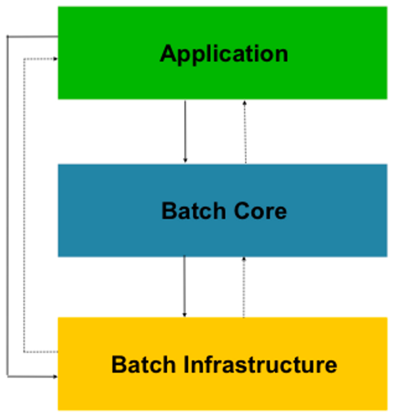
- 3개의 티어로 구성된 아키텍처(어플리케이션, 코어, 인프라스트럭처)
어플리케이션- 코어와 상호 작용코어- 잡, 스텝, 잡 런처, 잡 파라미터 등의 배치 도메인 요소들인프라스트럭처- 배치 처리를 위해 필요한 공통 인프라 제공
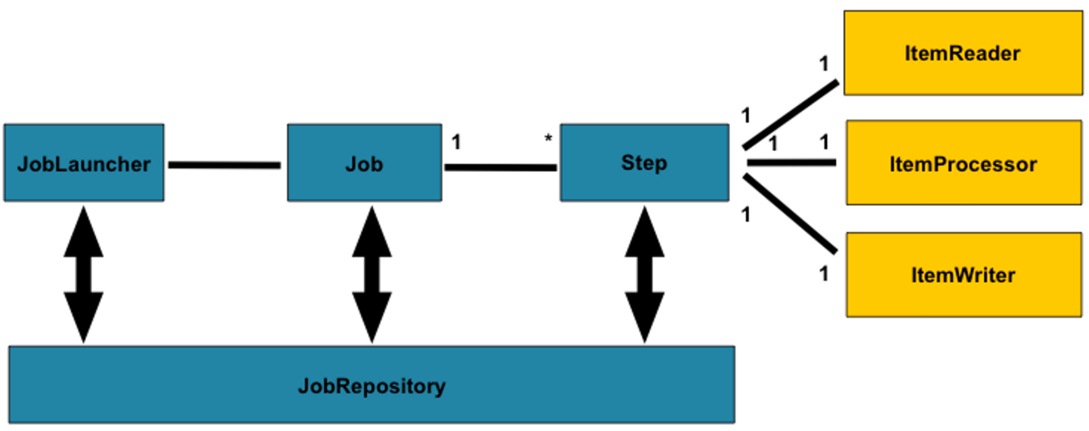
스프링 배치 도메인 언어
- 스프링 배치 어플리케이션을 작성하기 위해 필요한 요소
- Job
- JobInstance
- JobExecution
- JobParameter
- JobListener
- Step
- Tasklet 기반
- Chunk 기반
Job
- 스프링 배치의 실행 단위
- 여러 개의
Step을 포함하는 컨테이너 - 독립적이고 외부와 상호작용 없이 처음부터 끝까지 실행됨
- 스프링 빈으로 유일하게 등록됨
스프링 빈으로 유일하게 등록됨 예제
@Bean
public Job myJob(JobBuilderFactory jobBuilderFactory, Step step) {
return jobBuilderFactory.get("myJob") // ← 이름
.start(step)
.build();
}
여기서
myJob이라는 이름을 가진 Job이 스프링 컨테이너에 등록된다.
이 이름으로 또 다른 Job을 등록하려고 하면 충돌 발생!
왜 이렇게 설계됐을까?
스프링 배치는 Job을 실행할 때 이름으로 식별한다.
그래서 이름이 고유해야, 어떤 Job을 실행할지 정확하게 알 수 있다.
JobInstance란?
Job을 실행할 때 Job 이름 + Job 파라미터 조합으로 하나의 JobInstance가 생성
즉, “무엇을 어떤 조건으로 실행했는가?”를 기준으로 구분된다.
같은 Job 이름에 같은 파라미터로는 한 번만 실행 가능하다. (이미 실행했으면 재실행 불가)
재실행하고 싶다면 파라미터를 바꾸거나 Job 이름을 바꿔야 한다.
예시
JobParameters params1 = new JobParametersBuilder()
.addString("date", "2025-04-08")
.toJobParameters();
jobLauncher.run(myJob, params1);
이렇게 실행하면, myJob이라는 이름과 date=2025-04-08이라는 파라미터를 가진 JobInstance 하나가 만들어진다.
이걸 다시 실행하면?
jobLauncher.run(myJob, params1);
이미 같은 이름과 파라미터로 실행한 적 있기 때문에,
JobInstance already exists and is complete 같은 예외가 발생할 수 있다.
다시 실행 하고 싶다면?
JobParameters params2 = new JobParametersBuilder()
.addString("date", "2025-04-09") // 파라미터 값 변경
.toJobParameters();
jobLauncher.run(myJob, params2);
같은 조합은 한 번만 실행 가능, 재실행은 파라미터를 바꿔야 한다.
JobExecution
- Job을 실행한 것을 의미
- 실패든 성공이든 시도한 것을 나타낸다.
- JobInstance가 실제로 실행된 기록
- 하나의 JobInstance는 여러 번 실행될 수 있다. (예: 실패해서 재시도하는 경우)
- 각각의 실행 시도마다 JobExecution이 생성된다.
JobParameters params = new JobParametersBuilder()
.addString("date", "2025-04-08")
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(myJob, params);
System.out.println("Execution Status: " + jobExecution.getStatus());
여기서 jobExecution은 실제 실행 시도에 대한 정보이다.
실패하면 다시 시도 가능하고, 그때마다 새로운 JobExecution이 생성된다.
하지만 JobInstance는 동일한 것 (Job 이름 + 파라미터가 같으므로).
JobExecution은 아래와 같은 상태(status)를 가질 수 있다.
- STARTING
- STARTED
- FAILED
- COMPLETED
- STOPPED
- ABANDONED
JobParameter
- 잡에 전달되는 파라미터
JobListener
- Job의 시작 전/후에 실행되는 로직을 정의할 수 있게 해주는 콜백 인터페이스
- 흔히 로그 기록, 리소스 정리, 실행 시간 측정, 알림 발송 같은 걸 할 때 쓴다.
대표 인터페이스
JobExecutionListener 인터페이스가 가장 많이 쓰인다.
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution); // Job이 시작되기 바로 전에 호출됨
void afterJob(JobExecution jobExecution); // Job이 끝난 후에 호출됨 (성공이든 실패든)
}
Step
Job을 구성하고 있는 배치 작업의 독립적이고 순차적인 단위
- 주요 유형
- Tasklet 기반 Step
- 간단한 실행 처리
- Chunk 기반 Step
- 아이템 기반의 처리
- ItemReader
- ItemProcessor
- ItemWriter
- Tasklet 기반 Step
Tasklet
- Spring Batch에서 Step 안에서 처리할 작업을 정의하는 방식 중 하나
- 간단한 작업, 예를 들어 파일 삭제, 로그 출력, 초기화 작업 등 처리
- execute() 메서드 안에서 로직을 작성
- 하나의 트랜잭션 단위로 동작
- 리턴값
RepeatStatus.FINISHEDorRepeatStatus.CONTINUABLE
예: 날짜별 임시 파일 삭제
@Component
public class TempFileCleanupTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {
// 여기에 원하는 작업 로직 작성
File tempDir = new File("/tmp");
for (File file : tempDir.listFiles()) {
if (file.getName().endsWith(".tmp")) {
file.delete();
}
}
System.out.println(">>>>> Temporary files cleaned up.");
return RepeatStatus.FINISHED; // 한 번만 실행하고 종료
}
}
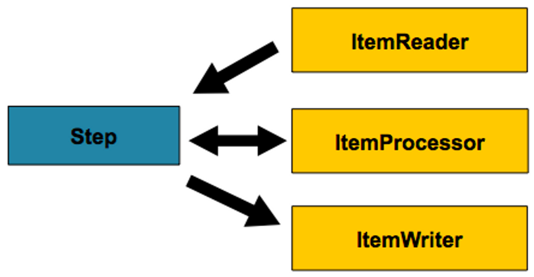
ItemReader, ItemProcessor, ItemWriter
이 구조는 Chunk 기반 처리에서 사용된다. 즉, 데이터를 일정 단위(예: 10개)씩 읽고 처리하고 쓰는 방식
ItemReader: 데이터를 읽어옴 (예: DB, 파일, API 등)ItemProcessor: 데이터를 가공/변환함 (선택사항)ItemWriter: 데이터를 저장/쓰기함 (예: DB, 파일 등)
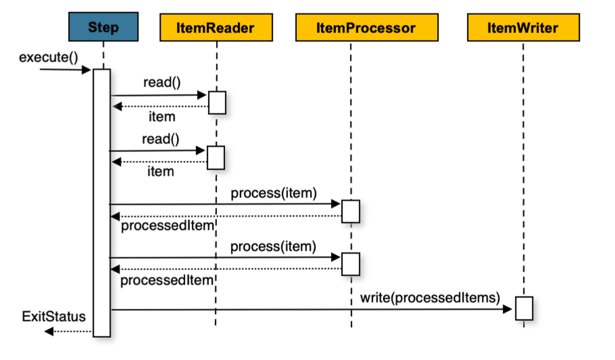
예시) CSV 파일 → 가공 → DB 저장 작업
- ItemReader: CSV 파일에서 고객 데이터 읽기
@Bean
public FlatFileItemReader<Customer> reader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("customerItemReader")
.resource(new ClassPathResource("customers.csv"))
.delimited()
.names("id", "name", "email")
.targetType(Customer.class)
.build();
}
- ItemProcessor: 이름을 대문자로 변경
@Component
public class CustomerItemProcessor implements ItemProcessor<Customer, Customer> {
@Override
public Customer process(Customer customer) {
customer.setName(customer.getName().toUpperCase());
return customer;
}
}
- ItemWriter: DB에 저장
@Bean
public JdbcBatchItemWriter<Customer> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Customer>()
.sql("INSERT INTO customer (id, name, email) VALUES (:id, :name, :email)")
.dataSource(dataSource)
.beanMapped()
.build();
}
Step에 등록
한 번에 10개씩 읽고 → 처리하고 → 저장
@Bean
public Step step(StepBuilderFactory stepBuilderFactory,
ItemReader<Customer> reader,
ItemProcessor<Customer, Customer> processor,
ItemWriter<Customer> writer) {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
ItemReader 종류
- FlatFileItemReader (예, csv 파일)
- StaxEventItemReader (예, xml 파일)
- JsonItemReader (예, json 파일)
- JdbcCursorItemReader (데이터베이스)
- JdbcPagingItemReader (데이터베이스)
- JpaPagingItemReader (데이터베이스)
- HibernateCursorItemReader (데이터베이스)
- StoredProcedureItemReader (데이터베이스)
ItemWriter 종류
- FlatFileItemWriter
- StaxEventItemWriter
- JsonFileItemWriter
- JdbcBatchItemWriter
- HibernateItemWriter
- JpaItemWriter
순서
스텝은 각 스텝과의 순서를 지정 가능
ex) StepA > StepB > StepC
@Bean
public Job job(JobRepository jobRepository){
return new JobBuilder("job", jobRepository)
.start(stepA())
.next(stepB())
.next(stepC())
.build();
}
분기
- Step은 실행 후 종료 ExitStatus 값을 확인해서 다음 Step을 정함
- on(“패턴”)을 통해 분기 조건 지정
- : 아무 문자든 다 매치 (와일드카드)
- ? : 정확히 한 글자 매치
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
.start(stepA()).on("FAILED").to(stepC())
.from(stepA()).on("*").to(stepB())
.end()
.build();
}